

Getting Started
Installation
npm install @memorilabs/memori
pip install memori
Quickstart
Sign up at app.memorilabs.ai, get a Memori API key, and start building. Full docs: memorilabs.ai/docs/memori-cloud/.
Set MEMORI_API_KEY and your LLM API key (e.g. OPENAI_API_KEY), then:
import { OpenAI } from 'openai';
import { Memori } from '@memorilabs/memori';
// Requires MEMORI_API_KEY and OPENAI_API_KEY in your environment
const client = new OpenAI();
const mem = new Memori().llm
.register(client)
.attribution('user_123', 'support_agent');
async function main() {
await client.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{ role: 'user', content: 'My favorite color is blue.' }],
});
// Conversations are persisted and recalled automatically in the background.
const response = await client.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{ role: 'user', content: "What's my favorite color?" }],
});
// Memori recalls that your favorite color is blue.
}
from memori import Memori
from openai import OpenAI
# Requires MEMORI_API_KEY and OPENAI_API_KEY in your environment
client = OpenAI()
mem = Memori().llm.register(client)
mem.attribution(entity_id="user_123", process_id="support_agent")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "My favorite color is blue."}]
)
# Conversations are persisted and recalled automatically.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What's my favorite color?"}]
)
# Memori recalls that your favorite color is blue.
Explore the Memories
Use the Dashboard — Memories, Analytics, Playground, and API Keys.
[!TIP] Want to use your own database? Check out docs for Memori BYODB here: https://memorilabs.ai/docs/memori-byodb/. For disposable BYODB development databases, see the TiDB Zero provisioning guide: docs/memori-byodb/databases/tidb.mdx.
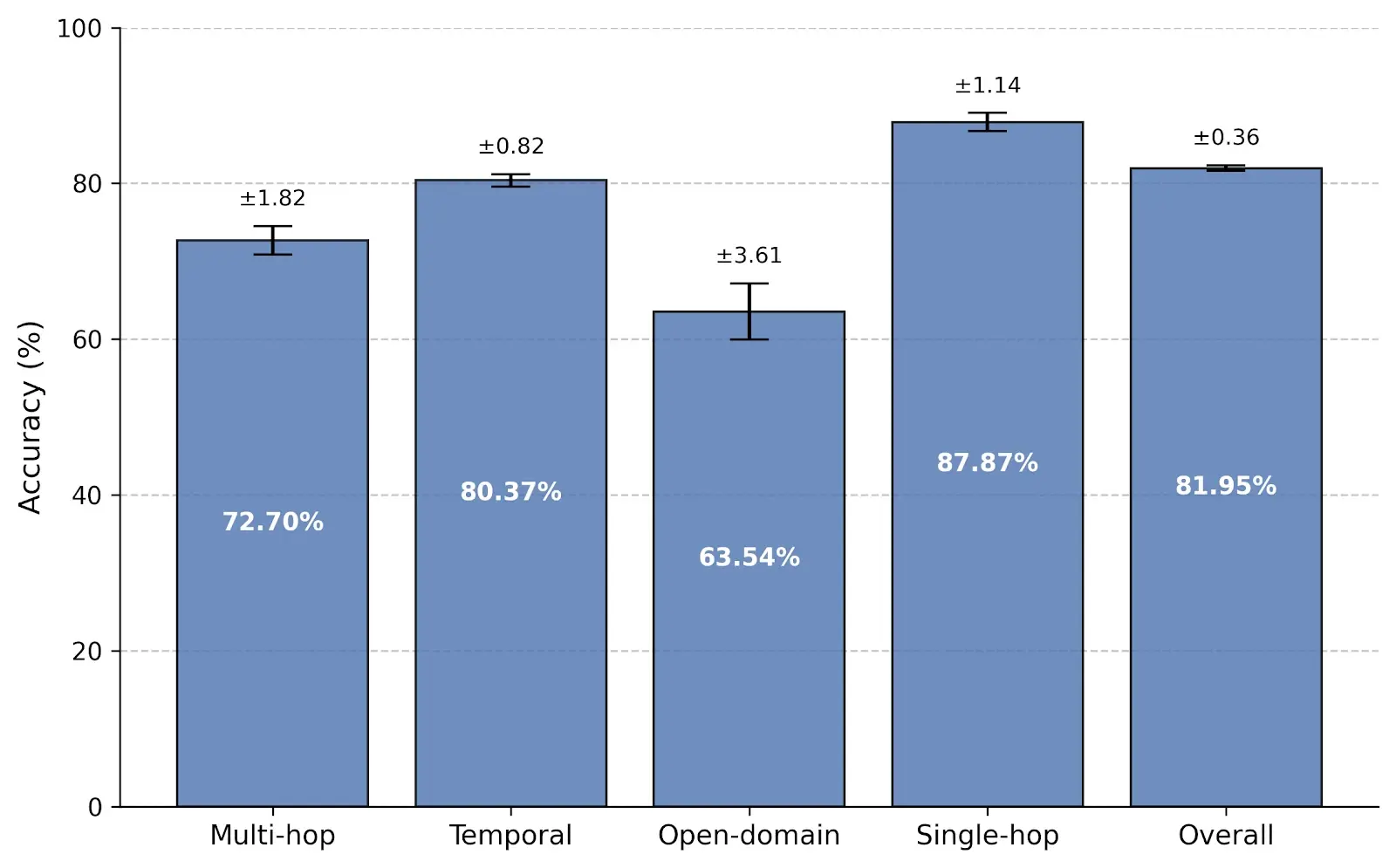
LoCoMo Benchmark
Memori was evaluated on the LoCoMo benchmark for long-conversation memory and achieved 81.95% overall accuracy while using an average of 1,294 tokens per query. That is just 4.97% of the full-context footprint, showing that structured memory can preserve reasoning quality without forcing large prompts into every request.
Compared with other retrieval-based memory systems, Memori outperformed Zep, LangMem, and Mem0 while reducing prompt size by roughly 67% vs. Zep and lowering context cost by more than 20x vs. full-context prompting.
Read the benchmark overview, see the results, or download the paper.
OpenClaw (Persistent Memory for Your Gateway)
By default, OpenClaw agents forget everything between sessions. The Memori plugin fixes that. It automatically captures structured memory from conversation and agent execution after each turn — including tool calls, decisions, and outcomes — and makes it available for agents to recall on demand.
No changes to your agent code or prompts are required. The plugin hooks into OpenClaw's lifecycle, so you get structured memory, agent-controlled recall, and Advanced Augmentation with a drop-in plugin.
openclaw plugins install @memorilabs/openclaw-memori
openclaw plugins enable openclaw-memori
openclaw memori init \
--api-key "YOUR_MEMORI_API_KEY" \
--entity-id "your-app-user-id" \
--project-id "my-project"
openclaw gateway restart
For setup and configuration, see the OpenClaw Quickstart. For architecture and lifecycle details, see the OpenClaw Overview.
Hermes Agent (Persistent Memory Provider)
Memori also ships as a Hermes Agent memory provider. It captures completed conversations in the background and gives Hermes explicit memori_recall and memori_recall_summary tools for agent-controlled recall.
pip install hermes-memori
hermes-memori install
hermes config set memory.provider memori
HERMES_HOME="${HERMES_HOME:-$HOME/.hermes}"
mkdir -p "$HERMES_HOME"
echo "MEMORI_API_KEY=YOUR_MEMORI_API_KEY" >> "$HERMES_HOME/.env"
echo "MEMORI_ENTITY_ID=your-app-user-id" >> "$HERMES_HOME/.env"
MEMORI_PROJECT_ID is optional; when omitted, the provider uses Hermes' active project context for scoping.
For setup and configuration, see the Hermes Quickstart. For architecture and lifecycle details, see the Hermes Overview.
MCP (Connect Your Agent in One Command)
Your agent forgets everything between sessions. Memori fixes that. It remembers your stack, your conventions, and how you like things done so you stop repeating yourself.
Works for solo developers and teams. Your agent learns coding patterns, reviewer preferences, and project conventions over time. For teams, that means shared context that new engineers pick up on day one instead of absorbing tribal knowledge over months.
If you use Claude Code, Cursor, Codex, Warp, or Antigravity, you can connect Memori with no SDK integration needed:
claude mcp add --transport http memori https://api.memorilabs.ai/mcp/ \
--header "X-Memori-API-Key: ${MEMORI_API_KEY}" \
--header "X-Memori-Entity-Id: your_username" \
--header "X-Memori-Process-Id: claude-code"
For Cursor, Codex, Warp, and other clients, see the MCP client setup guide.
Attribution
To get the most out of Memori, you want to attribute your LLM interactions to an entity (think person, place or thing; like a user) and a process (think your agent, LLM interaction or program).
If you do not provide any attribution, Memori cannot make memories for you.
mem.attribution("12345", "my-ai-bot");
mem.attribution(entity_id="12345", process_id="my-ai-bot")
Session Management
Memori uses sessions to group your LLM interactions together. For example, if you have an agent that executes multiple steps you want those to be recorded in a single session.
By default, Memori handles setting the session for you but you can start a new session or override the session by executing the following:
mem.resetSession();
// or
mem.setSession(sessionId);
mem.new_session()
# or
mem.set_session(session_id)
Supported LLMs
- Anthropic
- Bedrock
- DeepSeek
- Gemini
- Grok (xAI)
- OpenAI (Chat Completions & Responses API)
(unstreamed, streamed, synchronous and asynchronous)
Supported Frameworks
- Agno
- LangChain
- Pydantic AI
Supported Platforms
- DeepSeek
- Nebius AI Studio
Examples
For more examples and demos, check out the Memori Cookbook.
Memori Advanced Augmentation
Memories are tracked at several different levels:
- entity: think person, place, or thing; like a user
- process: think your agent, LLM interaction or program
- **ses